Turbocharging Address Autocomplete: Implementing In-Memory Caching with cache2k and Spring Boot
Learn how to 'turbocharge' your address autocomplete service by implementing in-memory caching in Spring Boot. This guide explores using cache2k for sub-10ms response times, non-blocking access, and resilient performance, turning a sluggish UI into a snappy user experience.
Author
Viruchith Ganesan
What is In-Memory Caching?
In-memory caching is the practice of storing frequently accessed data in the application’s RAM (Random Access Memory) rather than fetching it from a slower disk-based source (like a database or a search engine) every time.
Why is it important?
- Latency: Accessing RAM is orders of magnitude faster than a network call or disk I/O.
- Throughput: By serving requests from memory, your application can handle thousands of concurrent users without putting a strain on backend resources.
- Cost: Reducing hits to external systems (like a managed Solr cloud or an Oracle RDS) can lower operational costs and infrastructure overhead.
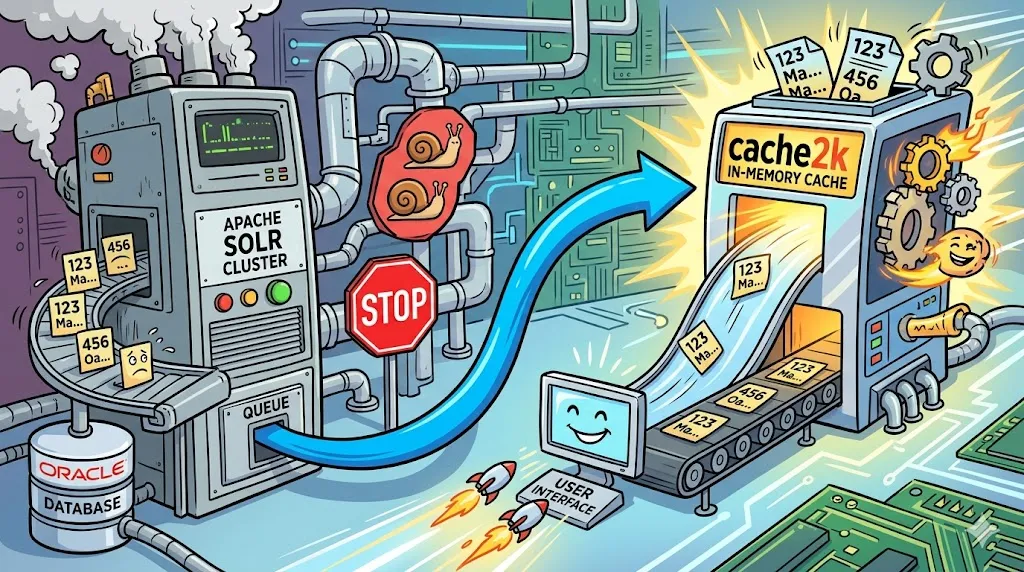
The Architecture: From Oracle to Autocomplete
Our system handles address auto completion—a feature where users type a few characters (e.g., “123 Ma…”) and get a list of suggested addresses.
- Source of Truth: An Oracle DB holds millions of address records.
- The Search Engine: An Apache Solr cluster (sharded for scale) indexes these addresses.
- The Synchronization: A nightly batch job refreshes the Solr index with the latest data from Oracle.
- The API: A Spring Boot REST service acts as the gateway for multiple consumers (web apps, mobile apps).
JCache: The Standard API
JCache is like a “universal remote.” It allows you to write code that works with any compliant caching library (Ehcache, Hazelcast, or cache2k).
- Best for: Staying vendor-neutral and ensuring your code is portable across different environments.
- Limitation: You are restricted to basic features and cannot easily use the advanced, performance-tuning “special features” unique to specific libraries.
Why cache2k?
While Caffeine and Ehcache are popular, cache2k stands out for its extreme performance, small footprint, and advanced features like “refresh-ahead” and “resilience.” For an autocomplete service where latency is the primary metric, cache2k provides non-blocking access that ensures the UI never hangs.
In modern web development, high-performance systems aren’t just about how fast your database is—they are about how rarely you have to talk to it. For Java and Spring Boot developers, in-memory caching is often the “secret sauce” that turns a sluggish UI into a “snappy” user experience.
In this article, we’ll explore a real-world use case: optimizing an address autocompletion service using cache2k, integrated within a Spring Boot REST application.
Implementation in Spring Boot
To implement this, we first add the dependency and then configure a CacheManager.
1. The Configuration
We define a cache specifically for address suggestions with a maximum capacity and an expiration time.
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public CacheManager cacheManager() {
SpringCache2kCacheManager manager = new SpringCache2kCacheManager("addressCacheManager");
manager.addCaches(b -> b.name("addressSuggestions")
.entryCapacity(10000) // Store up to 10k unique queries
.expireAfterWrite(24, TimeUnit.HOURS) // Matches our nightly DB refresh
.setupWith(SpringCache2kDefaultSupplier.class)
);
return manager;
}
}2. The Service Layer
Using Spring’s @Cacheable annotation, we can transparently cache the Solr results.
@Service
public class AddressService {
@Autowired
private SolrClient solrClient;
@Cacheable(value = "addressSuggestions", key = "#query.toLowerCase().trim()")
public List<String> getSuggestions(String query) {
// This logic only executes on a "Cache Miss"
SolrQuery solrQuery = new SolrQuery("address_search_field:" + query + "*");
QueryResponse response = solrClient.query(solrQuery);
return response.getResults().stream()
.map(doc -> (String) doc.getFieldValue("full_address"))
.collect(Collectors.toList());
}
}When to Use Caching
- Frequent Access to Static or Slow-Moving Data: If your data changes on a predictable schedule (like your nightly Oracle-to-Solr sync), caching is ideal. It prevents redundant, expensive trips to the database for information that hasn’t changed.
- High “Read-to-Write” Ratio: Caching shines when you read data hundreds of times for every one time it is updated. Autocomplete is a perfect example: users search for “Main Street” thousands of times, but the street name itself rarely changes.
- Computationally Expensive Operations: If your Solr query involves complex aggregations, fuzzy matching logic, or multi-shard joins that consume significant CPU, saving the result in memory prevents the search engine from “re-thinking” the same problem twice.
- Protecting Downstream Systems: Use a cache as a “buffer” to prevent your Solr shards or Oracle DB from being overwhelmed during peak traffic hours or during a Distributed Denial of Service (DDoS) event.
- Meeting Strict Latency SLAs: When your requirements demand sub-10ms response times (common for “search-as-you-type” UI components), network round-trips to external databases are often too slow. RAM is your only option.
When NOT to Use Caching
- Real-Time Data Requirements: If your users require “Absolute Truth” (e.g., bank account balances, stock trading prices, or seat availability for a concert), a cache can show dangerously stale information.
- Low Memory Environments: In-memory caching consumes the JVM Heap. If your application is running in a memory-constrained container (e.g., a small 512MB sidecar), a large cache can trigger frequent Garbage Collection (GC) pauses or OutOfMemoryErrors.
- Low Traffic / Rare Access: If a specific address is only searched once a month, caching it is a waste of resources. The “overhead” of managing that cache entry outweighs the benefit.
- High Write Volume: If the data changes every few seconds, the “Cache Invalidation” logic becomes so complex and frequent that the performance gain is negated by the constant effort to keep the cache updated.
- Very Large Datasets: If your total address database is 500GB, you cannot fit it in memory. In this case, you should rely on Solr’s internal indexing and disk-caching rather than trying to cache everything in your Spring Boot application’s RAM.