Architecting Privacy: Anonymous Indexing in FinTech and KYC Infrastructure
Learn how anonymous indexing (blind indexing) secures sensitive PII in FinTech and KYC pipelines. Discover the technical architecture required to run high-speed database queries over strongly encrypted data without sacrificing performance or compliance.
Author
Viruchith Ganesan

FinTech and banking architectures operate within a challenging constraint: they must comply with strict data privacy mandates (such as GDPR, PCI-DSS, and local central bank regulations) while maintaining a high-performance application layer capable of sub-millisecond database lookups.
When a system handles sensitive Personally Identifiable Information (PII)—such as National ID numbers, passport details, or tax identifiers during a Know Your Customer (KYC) onboarding pipeline—the data must be strongly encrypted at rest. However, strong modern encryption (like AES-256-GCM) utilizes randomized Initialization Vectors (IVs), meaning the same plaintext string yields a completely different ciphertext every time it is encrypted. This destroys the database’s ability to index the column, turning exact-match queries into costly, unindexed full-table scans.
Anonymous Indexing (frequently referred to in application security as Blind Indexing) solves this dilemma. It decouples the ability to search data from the ability to read it, allowing databases to perform high-speed index lookups on encrypted datasets without ever possessing the decryption keys or exposing the underlying plaintext.
The Core Mechanism: How It Works
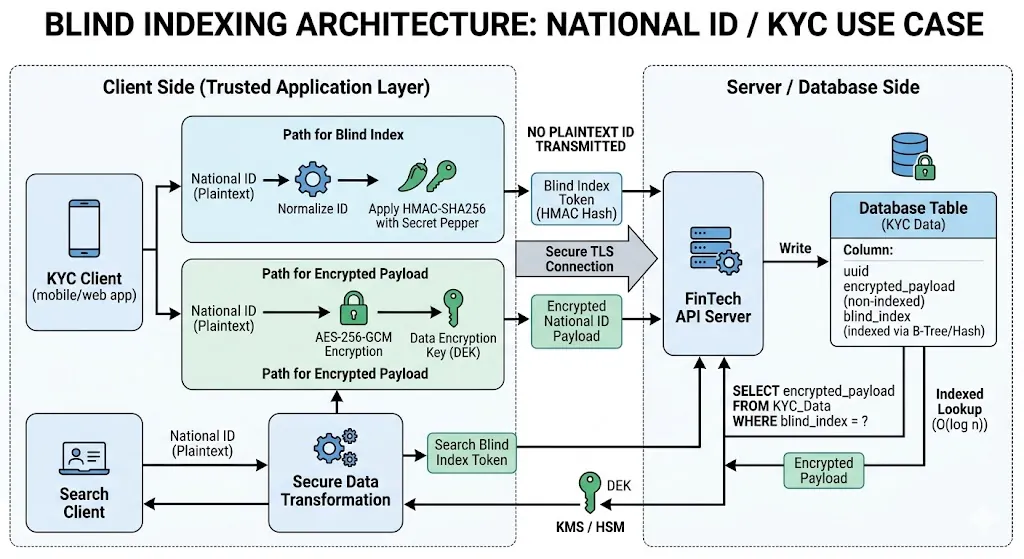
An anonymous index is a deterministic, cryptographically secure token stored alongside the encrypted data. While the primary data column is safely locked behind randomized, non-deterministic encryption, the index column contains a heavily protected hash of the data.
To keep the database engine completely “blind,” all cryptographic transformations occur upstream in the isolated application layer or within a secure hardware security module (HSM).
The Mathematical & Logical Flow
To generate an anonymous index, the raw PII is processed through a Keyed-Hash Message Authentication Code (HMAC) combined with a highly guarded, server-side secret key (often called a pepper) that is stored entirely outside the database cluster.
Anonymous Index=HMAC-SHA256(Normalized PII,Secret Pepper)
By using a dedicated secret pepper distinct from the data encryption keys, even a bad actor who gains full root access to the database layer cannot reverse-engineer or brute-force the index columns.
Technical Implementation Blueprint
Implementing an anonymous index requires a coordinated design across your data ingestion layer, application services, and database schema.
1. Database Schema Architecture
In a relational or document database, the PII record is split into three distinct functional columns: a unique identifier, the non-deterministic encrypted payload, and the deterministic anonymous index token.
| Column Name | Data Type | Database Index | Purpose |
|---|---|---|---|
user_id | UUID | Primary Key | Internal relational mapping. |
encrypted_national_id | TEXT | None | The secure payload (encrypted via AES-256-GCM). |
national_id_anon_idx | VARCHAR(64) | B-Tree / Hash Index | The anonymous blind lookup token. |
2. The Data Ingestion Lifecycle (Write Path)
When a user submits their National ID during a KYC check, the backend application processes the data through the following pipeline:
3. Execution Code Example (Python/Pseudocode)
import hashlib
import hmac
import os
from cryptography.hazmat.primitives.ciphers.aead import AESGCM
# Cryptographic secrets retrieved from an external Key Management Service (KMS)
ENCRYPTION_KEY = os.environ.get("KMS_AES_KEY")
INDEX_PEPPER = os.environ.get("KMS_PEPPER_SECRET").encode('utf-8')
def generate_anonymous_index(plaintext_pii: str) -> str:
# Step 1: Normalize string to ensure deterministic matching
normalized = plaintext_pii.strip().lower().replace("-", "")
# Step 2: Generate Keyed Hash (HMAC) using the dedicated pepper
hashed = hmac.new(INDEX_PEPPER, normalized.encode('utf-8'), hashlib.sha256).hexdigest()
return hashed
def encrypt_payload(plaintext_pii: str) -> bytes:
aesgcm = AESGCM(ENCRYPTION_KEY)
nonce = os.urandom(12) # Non-deterministic initialization vector
ciphertext = aesgcm.encrypt(nonce, plaintext_pii.encode('utf-8'), None)
return nonce + ciphertext # Prepend nonce for storage
# Application-level save routine
def save_kyc_record(user_id, raw_national_id):
anon_idx = generate_anonymous_index(raw_national_id)
encrypted_payload = encrypt_payload(raw_national_id)
# Execute database insertion
db_execute(
"INSERT INTO kyc_data (user_id, encrypted_national_id, national_id_anon_idx) VALUES (%s, %s, %s)",
(user_id, encrypted_payload, anon_idx)
)
4. The Query Execution Lifecycle (Read Path)
To look up a user record by their document identifier, the application does not execute a wild wildcard search. It computes the single target anonymous index value first:
-- The application computes the hash upstream and executes an exact, indexed index search
SELECT encrypted_national_id
FROM kyc_data
WHERE national_id_anon_idx = 'e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855';
The database engine leverages its internal B-Tree index structure to pinpoint the row in time, entirely unaware of what document or user it is verifying.
Critical Applications in FinTech & KYC Environments
1. Identity Deduplication and Sybil Attack Prevention
A common fraud vector in FinTech involves malicious actors attempting to open dozens of digital wallets or bank accounts using a single compromised or stolen National ID combined with varying synthetic names or email addresses.
To prevent this, the KYC pipeline must perform a “uniqueness check” during onboarding. By querying the incoming document’s anonymous_index against the database, the system can instantly identify if that specific credential has been registered before. The database flags the duplicate fingerprint immediately, keeping the underlying data fully encrypted and protected from internal operational exposure.
2. Real-Time Anti-Money Laundering (AML) & Sanction Screening
FinTech networks are required to screen incoming applications against global sanction updates and Politically Exposed Persons (PEP) registries.
- Governments and compliance agencies publish updated hash registries of blocked entities.
- By storing customer profiles under standardized anonymous indexes, transaction engines can continuously cross-reference database keys against external blacklist hashes via high-speed, stream-processing joins, avoiding the need to decrypt millions of customer records during batch processing operations.
3. Zero-Knowledge Compliance Auditing
Financial regulators routinely audit FinTech platforms to ensure identity verification logs are fully maintained. With anonymous indexing structures, engineering teams can provide regulatory auditors with a read-only database dump containing nothing but the cryptographic hashes and encrypted blobs.
The audit team can then compute the hashes of a selected testing sample on their own local machines and verify that the records exist inside the production system ledger, fulfilling compliance tracking requirements without transferring or exposing plain text PII over auditing networks.
Advanced Engineering Trade-offs & Mitigation
| Engineering Challenge | Security Risk | Architectural Mitigation Strategy |
|---|---|---|
| Frequency Analysis Attacks | If an attacker steals the database, they can count identical anonymous index entries to deduce common values (e.g., common surnames or regional ID prefixes). | Truncation: Truncate the resulting anonymous index hash to a fixed length (e.g., 12 to 16 characters). This induces controlled hash collisions, forcing the application layer to resolve the minor subset of matches while preventing database-wide frequency graphing. |
| Lack of Range / Fuzzy Searches | Deterministic hashes do not support inequalities (>, <) or partial matches (LIKE '%text%'). | Phonetic Sidecar Indexes: If partial string matching is a strict requirement for names, compute anonymous indexes using phonetic or structural reduction algorithms (such as Double Metaphone or Soundex codes) before applying the HMAC pepper. |
| Secret Pepper Compromise | If the application server is fully breached along with the database, the attacker can brute-force the anonymous indexes. | Hardware Security Modules (HSM): Delegate the anonymous index generation process entirely to an external KMS or HSM pipeline equipped with rate-limiting controls to prevent massive bulk-hashing attacks. |