Eliminating Microservice Blind Spots: Introducing Project VEGA, an Open-Source GraphRAG Architecture Engine
Tired of microservice documentation going instantly obsolete? Discover the proposal for Project VEGA, a secure, zero-trust GraphRAG discovery engine built on SvelteKit.
Author
Viruchith Ganesan

In modern enterprise environments operating at scale, decoupled architectures, microservices, and independent codebases are vital for accelerating development velocity. However, this extreme decentralization introduces a systemic friction point: the slow, painful erosion of macro-level system visibility.
To combat this, we are outlining a conceptual blueprint for Project VEGA (Virtual Enterprise Graph Architecture)—a DOOM-inspired, hyper-efficient architecture discovery engine designed to be built entirely on Free and Open Source Software (FOSS). By trading heavy runtime overhead for a streamlined, asynchronous indexing approach, VEGA is proposed as a permanent solution to the enterprise discovery deficit.
Here is the technical proposal for VEGA, designed to utilize SvelteKit to drive a lightning-fast, reactive visualization workspace.
1. Problem Statement
As software organizations mature from monolithic frameworks into highly distributed microservices, the functional reality of their codebases becomes deeply siloed. This structural fragmentation regularly manifests in four critical enterprise pathologies:
-
Massive Tribal Knowledge Dependencies: High-level system architecture shifts from documented diagrams to “tribal knowledge” locked inside the heads of a few senior engineers.
-
Severe Discovery Deficits: When designing a new application, software architects routinely spend weeks trapped in discovery meetings, tracking down Slack threads, or digging through outdated wiki pages just to understand what infrastructure already exists.
-
Systemic Effort Duplication: Because individual engineering silos lack direct, macro-level visibility into neighboring repositories, teams routinely waste hundreds of developer hours building identical utility libraries or standalone microservices.
-
Instantly Obsolete Documentation: Traditional Enterprise Architecture (EA) modeling platforms depend heavily on manual registry updates. The moment an engineer modifies a configuration file or changes an API route in a continuous deployment pipeline, the existing static diagrams become entirely useless.
2. Example Scenarios
To understand the concrete real-world friction VEGA aims to target, consider how the implementation of an automated discovery layer would completely shift engineering efficiency:
Scenario A: Designing a Geo-Fencing Feature Without VEGA
An architect receives a core requirement: Implement a real-time geo-fencing service for delivery tracking.
-
The Manual Friction: Lacking a unified search layer, the architect drafts an entirely new system design from scratch, scheduling synchronization meetings with three different engineering leads to ensure no conflicts occur.
-
The Failure Mode: Due to blind spots across hundreds of disconnected repositories, the architect completely overlooks that Team C built an internal
location-utilslibrary two years prior, and Service X already actively tracks driver coordinate streams. The company spends weeks building a redundant codebase, directly multiplying their technical debt and infrastructure bills.
Scenario B: The Proposed VEGA Workflow
Faced with the exact same tracking requirement, the architect would avoid scheduling initial exploratory calls entirely. Instead, they would open the proposed VEGA natural-language dashboard and query the engine directly.
-
The Automated Insight: In milliseconds, VEGA would scan the structural metadata of the enterprise graph and explicitly surface the matching technical footprints. It would alert the architect that Team C’s pre-existing code contains a 95% structural match for the mathematical calculations required, and Service X already manages the necessary streaming data paths.
-
The Outcome: The architect transforms immediately from an active manual researcher to a system validator. They can draft a modification plan leveraging the existing primitives and bring the respective project owners into a single, final sign-off session to review the visual blueprint.
3. Proposed Solution
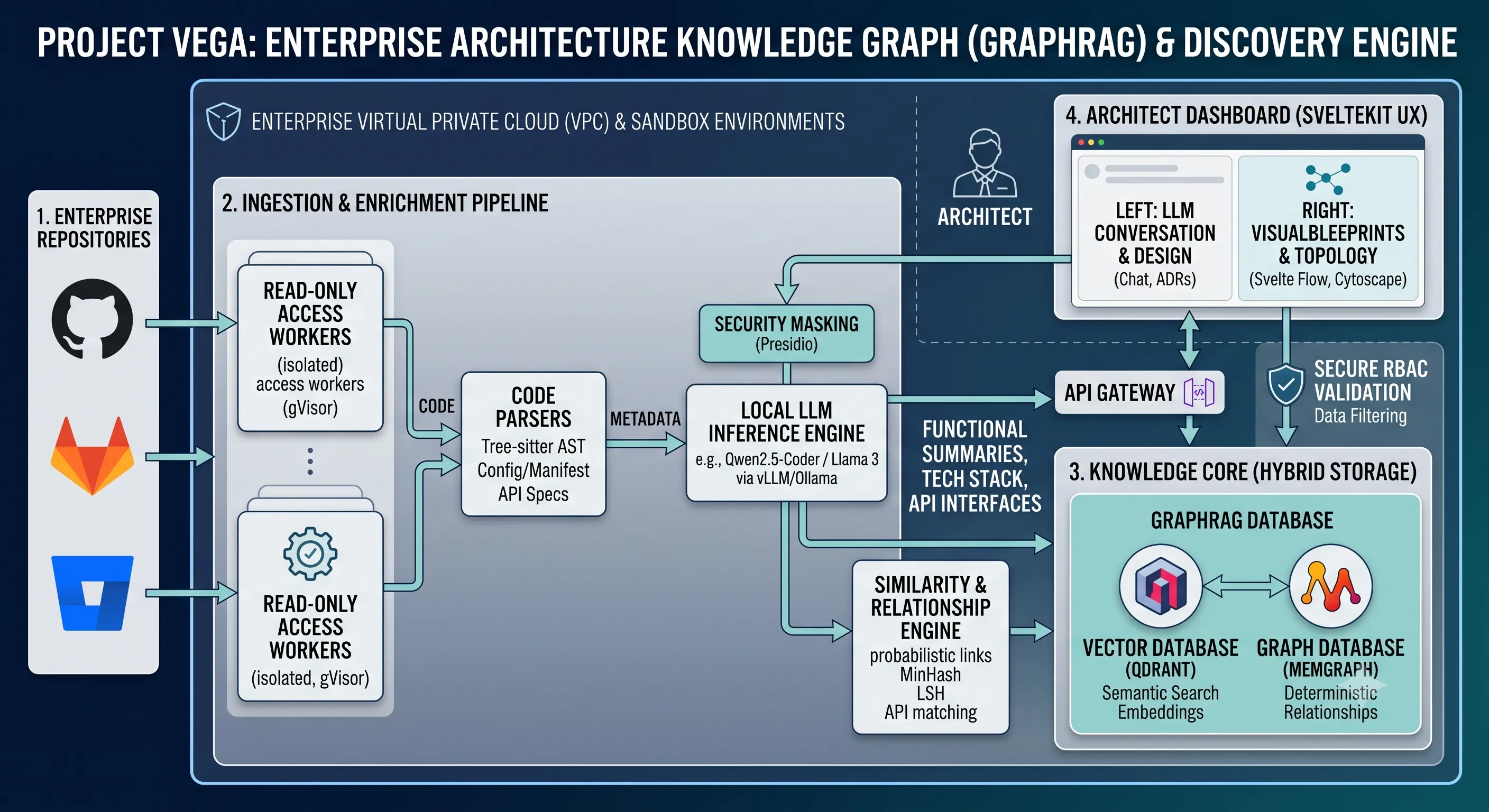
Project VEGA is conceptualized as an omniscient, hyper-efficient, and lightweight architecture discovery framework designed to continuously index an organization’s engineering ecosystem. Instead of forcing developers to manually document their code, the proposed application would hook directly into Version Control Systems (like GitHub or GitLab) and CI/CD pipelines to harvest non-intrusive “structural blueprints”.
The proposal specifies strictly utilizing FOSS technologies to keep its operational footprint small, lightning-fast, highly scalable, and completely compatible with air-gapped, sandboxed corporate networks. It is planned to act as a specialized GraphRAG (Graph Retrieval-Augmented Generation) engine.
By passing structural, language-agnostic code skeletons through localized, open-weights Large Language Models, VEGA would generate concise semantic summaries. These summaries would be indexed simultaneously into dual-storage cores: a vector database for semantic, intent-based searches, and an in-memory graph database for absolute, deterministic relationship mapping. The resulting platform would function as a force multiplier for software architects—giving them immediate clarity on what code exists, how applications converse, and exactly where true architectural gaps reside.
4. Technical Architecture
The proposal splits VEGA’s responsibilities across five distinct layers to maximize accuracy while minimizing computational token consumption:
A. The Ingestion & Parsing Pipeline (The “Extractor”)
To avoid inflating token usage and causing LLM hallucinations, the proposed pipeline entirely avoids reading lines of heavy business logic, loops, or conditional statements. Instead, an ephemeral ingestion worker would run inside a network-isolated, gVisor-hardened container to extract the structural skeleton of a repository:
-
Dependency Manifests: Parses files like
package.json,pom.xml,go.mod, andrequirements.txtto instantly capture framework configurations and upstream dependencies. -
Interface Definitions: Scans for Swagger/OpenAPI specifications, GraphQL schemas, and gRPC
.protofiles to deduce exact network entry points and payload structures. -
Abstract Syntax Tree (AST) Extraction: Employs Tree-sitter—an ultra-fast, C-based incremental parsing library—to strip away syntax and isolate high-level class hierarchies, public method configurations, and inline docstrings.
B. The Enrichment Layer (Local LLM Engine)
Once the extraction tool aggregates this metadata into a consolidated JSON “Application Skeleton”, the system is designed to map it to a locally hosted, specialized code model (such as Qwen2.5-Coder-7B or Llama-3-8B) operating via a high-throughput vLLM or Ollama runtime inside the company’s secure VPC. The LLM would perform a single, fast inference pass to return a standardized triad of data:
-
Functional Summary: A brief description detailing the core domain capability (e.g., “Validates user JWT authentication tokens and handles internal RBAC roles”).
-
Technical Stack Summary: A crisp breakdown of languages, databases, and structural libraries used.
-
Interface Summary: An organized list mapping exposed network routes and messaging topic subscriptions.
C. The Knowledge Core (Hybrid GraphRAG Storage)
The proposal coordinates a unified storage system to support both semantic discovery and strict network exploration:
-
Vector Database (Qdrant): Chosen for its Rust-based build providing maximum speed and memory efficiency, Qdrant would store the LLM-generated text embeddings using a local embedding model (e.g.,
BAAI/bge-large-en) to handle semantic, natural-language searches. -
Graph Database (Memgraph): A high-performance, C++ based in-memory graph database proposed to map explicit, deterministic architecture edges. Node graphs would track strict interactions:
(App:OrderService) -[DEPENDS_ON]-> (Library:KafkaClient) -[COMMUNICATES_WITH]-> (Infrastructure:KafkaCluster). -
Multi-Modal Relationship Similarity Engine: For legacy codebases lacking explicit dependency tracking, VEGA would programmatically infer implicit links. The plan involves applying Cosine Similarity to cross-examine matching inbound/outbound OpenAPI payload definitions, utilizing Jaccard Similarity string-matching across environment variables to pair disconnected Kafka producers and consumers, and computing Locality-Sensitive Hashing (MinHash/LSH) over Tree-sitter AST nodes to instantly expose duplicate code clones across different business units.
D. The Frontend Visualization Layer (SvelteKit Workspace)
The entire proposed architectural interface would be delivered via a SvelteKit dashboard. SvelteKit’s compile-time optimizations and state handling are intended to provide a fluid, responsive experience for architects slicing through large graphs.
-
The Split-Pane Layout: The workspace is designed with a coordinated dual-pane configuration. The left pane would host a clean markdown interface driving conversational interaction with the local model, rendering real-time Architecture Decision Records (ADRs).
-
The Topology Engine: The right pane would map machine data into rich visual representations. It is planned to integrate Svelte Flow (the highly declarative, Svelte-native counterpart to React Flow) to construct dynamic, node-based, draggable architecture blueprints directly from LLM proposals.
-
Blast Radius Simulations: When an architect requests a deep-dive dependency assessment, SvelteKit would leverage Cytoscape.js. Cytoscape would execute physics-based, force-directed layouts to model hundreds of deep microservice relationship loops with real-time, hardware-accelerated rendering.
E. Zero-Trust Data Security
Because VEGA is conceived to parse sensitive enterprise intellectual property, security is embedded directly into the system’s proposed runtime parameters:
-
Ephemeral Sandboxing: Ingestion workers would execute code parsing with network egress completely blocked, ensuring zero data leakage. Raw source files would be processed entirely in-memory and immediately destroyed; no source code is ever to be written to persistent storage disks.
-
Pre-LLM Masking: Skeletons would traverse an open-source redaction pipeline (Microsoft Presidio) to scrub accidental hardcoded API keys, configuration passwords, or Personally Identifiable Information (PII) before records ever reach the databases.
-
Repository-Mirroring RBAC: Every node injected into Qdrant or Memgraph would be cryptographically tagged with a metadata
RepoIDmatching its source Git permissions. When a user searches VEGA, the engine is designed to automatically inject a security filter directly into the vector and graph queries. If an architect does not possess explicit read access to a highly confidential repository within the corporate Git provider, VEGA would mathematically filter out those nodes, ensuring the restricted infrastructure remains completely invisible to the LLM context.
Checkout the project repository for the full technical proposal - https://github.com/viruchith/VEGA.